NLQueryFlow: Building a Natural Language Query Engine for Admin Dashboards
Admins often need to answer complex questions about user data, fast. Questions like:
- "Show active designers who heard about us from LinkedIn"
- "Users open to work from the last 30 days"
- "Now include PMs also"
Traditional filter UIs can do this, but they're slow for exploratory analysis. So I built NLQueryFlow, a system that lets admins type questions in plain English and get back scoped, paginated results with analytics and export support.
The core idea: LLM decides intent, deterministic backend enforces truth.
How It Works (High Level)
NLQueryFlow is a 3-layer pipeline:
- Admin types a natural language query in the UI.
- A GenAI planner converts that intent into a structured filter contract (JSON, not SQL).
- The backend validates the plan, builds a safe DB query, and returns results.
This gives the speed of natural language with the predictability of strict, typed contracts.
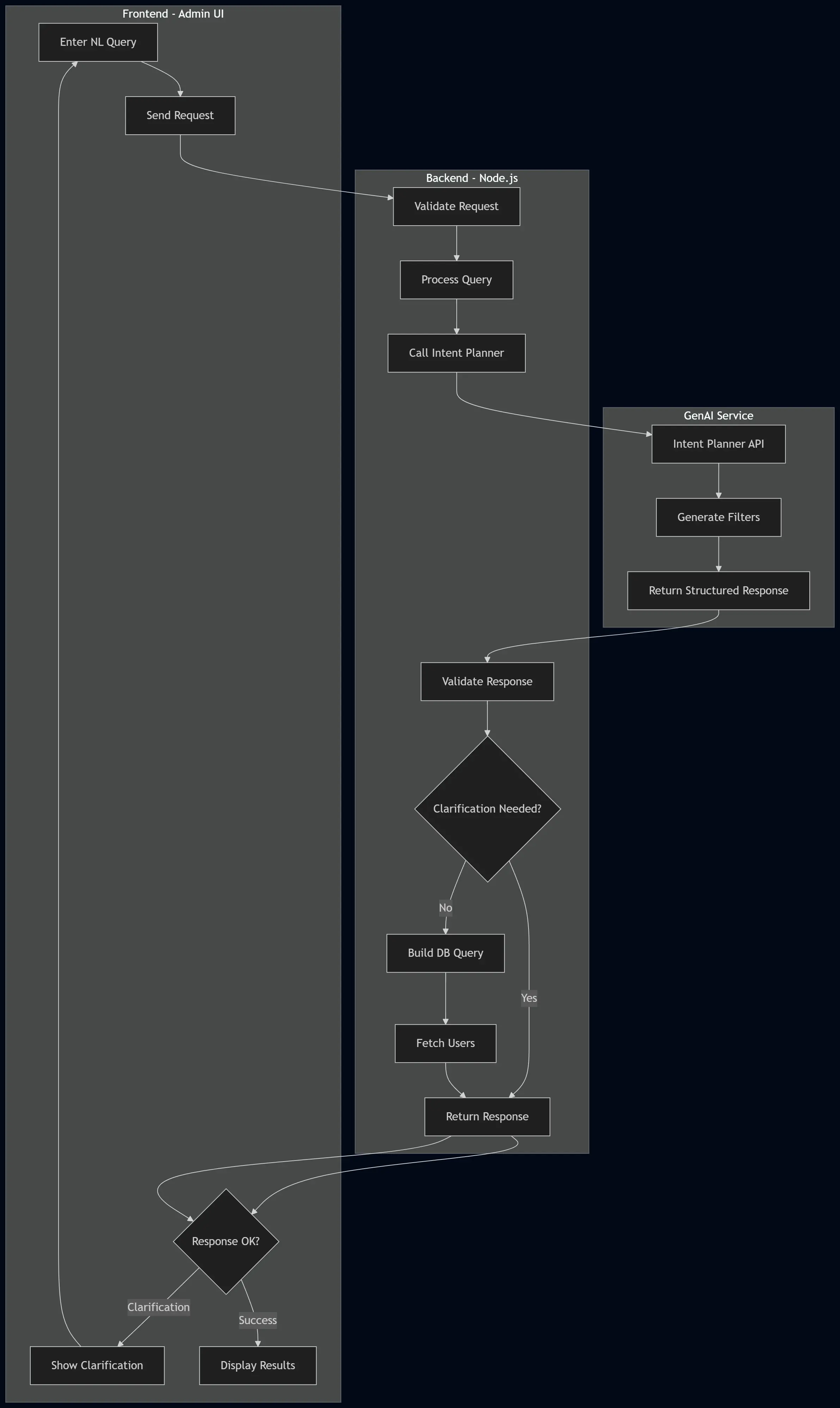
Frontend
The admin UI component owns:
- NL conversation state
- current filters and meta state
- query submission and follow-up handling
- clarification and broad-query confirmation UX
- table, charts, and export orchestration
What gets sent to the backend on each query
Every request includes both the natural language input and the current deterministic context:
{
"query": "Show active designers from LinkedIn",
"conversationId": "abc123",
"conversation": [...],
"currentFilters": { ... },
"currentMeta": { ... },
"isFollowUp": false,
"confirmBroadQuery": false
}
Sending the full filter/meta state alongside the NL query is critical. It lets follow-up turns safely merge or replace existing constraints without re-deriving everything from scratch.
Two response modes
Clarification needed:
- Displays a clarification question to the admin
- Keeps current query context for the next turn
- Optionally requests explicit confirmation for broad/unconstrained queries
Final answer:
- Applies the returned
appliedFilters - Applies normalized
meta(page, limit, scope, date range, sort) - Refreshes the scoped user list and analytics views
Backend
Request flow
The API route is protected by admin token middleware. On each request:
- Validates the request body and auth
- Calls the GenAI intent planner with the query + current context
- Validates the planner response shape
- Normalizes filters and meta
- Merges or replaces constraints depending on mode
- Triggers clarification if needed
- Compiles the DB query and fetches paginated users
- Returns results with a debug/explanation envelope
Guard and normalization layer
This is where NL output gets made safe and predictable. A dedicated utilities module handles:
- Request body validation
- Filter normalization to a canonical
filterGroupsshape - Merge vs. replace semantics for follow-up queries
- Meta normalization and range clamping
- Broad-query detection (unconstrained queries that would return too many results)
- MongoDB query compilation
- Deterministic explanation/debug generation
Shared filter contract
The planner's allowed output vocabulary is defined in a versioned JSON contract shared across the backend and GenAI service. This constrains enum values and mapping rules, which dramatically reduces prompt drift and parser ambiguity across deployments.
GenAI Planner (Python)
The planner service is a standalone Python microservice. Its job is to convert a natural language query (plus context) into a strict JSON filter plan.
Input
{
"query": "Show active designers from LinkedIn",
"schemaVersion": "1.2",
"currentFilters": { ... },
"currentMeta": { ... },
"conversationHistory": [...],
"plannerContextFlags": { ... }
}
Output
{
"mode": "merge",
"requestedFilters": {
"filterGroups": [
{
"currentStatus": "active",
"primaryRole": "designer",
"source": "linkedin"
}
]
},
"meta": { "page": 1, "limit": 20, "scope": "all" },
"clarificationNeeded": false,
"clarificationQuestion": null,
"confidence": 0.94
}
Note: the output is structured filters, not SQL. The backend owns all DB logic.
Reliability strategy
This is the part I'm most proud of. Raw LLM output is unreliable, so the planner uses a multi-step safety pipeline:
- Prompt the model for JSON-only output (using Gemini)
- Robustly extract and parse JSON from model text
- Validate with strict Pydantic models
- Normalize to contract-compliant enums and shapes
- If validation fails, retry with a schema-repair prompt
- If still invalid, return a deterministic fallback with
clarificationNeeded: true
This is the primary reason the system is reliable even when input is ambiguous. It never returns malformed filters, it asks for clarification instead.
Filter Representation
Filters use a filterGroups structure: OR across groups, AND within each group. This maps naturally to how admins think:
{
"filterGroups": [
{ "primaryRole": "designer", "currentStatus": "active" },
{ "primaryRole": "pm", "currentStatus": "active" }
]
}
This represents (active designers) OR (active PMs), which is exactly what "Show active designers and PMs" means.
End-to-End: Happy Path
- Admin submits NL query in the UI
- Frontend posts NL payload + current filter/meta context
- Backend validates body and admin auth
- Backend asks the GenAI planner for a structured intent plan
- GenAI returns a canonical filter/meta response
- Backend normalizes, merges/replaces constraints
- Backend compiles MongoDB query, fetches paginated users
- Backend returns
appliedFilters,meta,results, and explanation - Frontend renders matched users, segment analytics, and enables CSV export
End-to-End: Clarification Path
- Planner marks
clarificationNeeded: trueOR backend detects an unconstrained broad query - Backend returns clarification payload without executing the heavy user query
- Frontend displays the clarification question; admin can also explicitly confirm broad query
- Admin responds; next turn proceeds with updated context
Safety and Guardrails
Every boundary in this system validates:
- Auth (admin token middleware)
- Schema version alignment
- Strict response shape checks from the planner
- Enum canonicalization (unknown values get flagged, not silently passed through)
- Date range, scope, and limit normalization
- Broad-query confirmation before running expensive queries
- Clarification-first behavior for ambiguous inputs
Failure behavior is always safe: upstream planner errors map to safe API errors, invalid planner output triggers a repair retry, and the final fallback returns a clarification-required response rather than malformed filters.
Performance Considerations
Already in place:
- Pagination and max-limit controls
- Constrained sort fields
- Projection-based DB fetches (only fetch needed fields)
- Parallel count + list query execution
- Capped OR groups to avoid query explosion
Things I'd add next:
- Index review for high-frequency filter fields (
role,status,source, etc.) - Structured metrics and tracing around planner latency and normalization outcomes
- Selective caching for repeated scoped analytics requests
- Standardized error surfacing across all frontend fetch paths
Testing Strategy
Current test coverage includes:
- Guard and normalization unit tests
- Filter contract integrity tests (backend)
- Planner intent accuracy tests (GenAI service)
Recommended additions:
- End-to-end integration tests for clarification loops
- Regression tests for merge vs. replace follow-up scenarios
- Load tests for the broad-query confirmation path
Key Engineering Decisions
1. NL for intent, not execution
The model decides what the admin wants. The backend decides what actually runs. These are intentionally separate concerns.
2. Shared contract as source of truth
A versioned filter contract keeps all three layers aligned. When the contract changes, prompt drift and parser mismatches surface immediately.
3. Clarification-first over noisy results
If intent is ambiguous or unconstrained, the system asks before querying, not after returning confusing data.
4. Normalize everywhere
Normalization and validation happen at multiple system boundaries, not just once at entry. This makes the system robust to partial failures and model inconsistency.
Conclusion
NLQueryFlow works because it treats LLM output as a planning signal, not a direct data query.
The architecture balances:
- Usability: natural language and fast multi-turn follow-ups
- Correctness: contract-driven normalization and strict validation
- Safety: clarification loops, auth, and guardrails at every layer
- Scalability: deterministic backend execution with pagination and projection controls
If you extend something like this, keep the same principle: let AI propose intent, let deterministic services enforce truth.
End of file.